vite.js로 구성한 react.js가 어느 순간에 포트가 박혀벼리는 현상이 발생했다

검색해보니 윈도우 포트가 잠겼을때 발생하는 현상으로 자주 보고 되는듯 하다.
해결법
1. Posershell 관리자로 실행
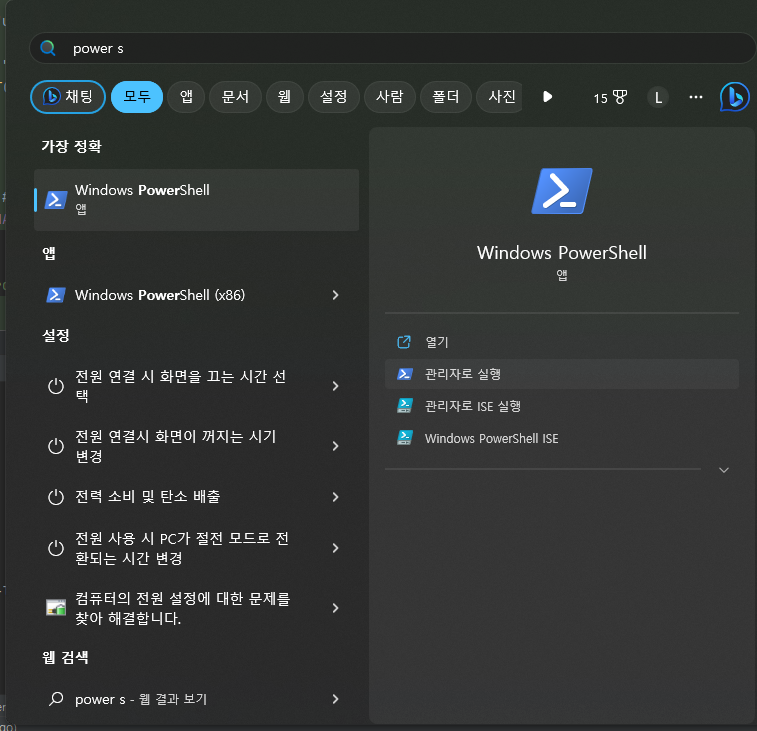
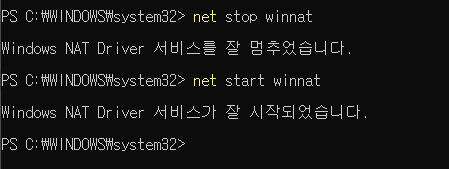
2. 명령어 입력 (winnat 서비스 종료 후 재기동)
vite.js로 구성한 react.js가 어느 순간에 포트가 박혀벼리는 현상이 발생했다
검색해보니 윈도우 포트가 잠겼을때 발생하는 현상으로 자주 보고 되는듯 하다.
해결법
1. Posershell 관리자로 실행
2. 명령어 입력 (winnat 서비스 종료 후 재기동)
Pentaho는 Java기반의 Database 데이터 마이그레이션 기능을 지원하는 오픈소스 툴이다.
막연히 Windows에 설치하고 Pentaho를 실행하면 뜨질 않는다.
자잘한 환경 변수 설정을 해줘야하는데, 그 전에 Java가 설치되어 있어야한다.
1) 오라클 계정 (Java 다운로드시 필요)
2) 윈도우 8 or 10
3) 환경 변수를 설정 할 수 있는 권한
4) Java를 설치 할 수 있는 권한
아래의 링크를 클릭하여 zip파일을 다운로드 받은 후 원하는 위치에 압축을 푼다.
-> 다운로드
아래의 링크를 클릭하 Java 설치 파일을 다운로드 받는다. (64Bit 기준)
-> 다운로드
이 후 Installer 를 이용하여 Java를 설치하게 되면 C:\Program Files\java 폴더의 구조는 아래의 화면처럼 구성된다.
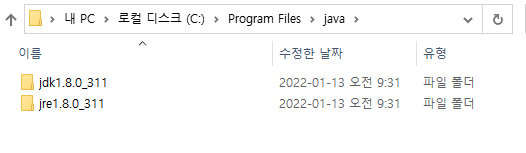
jdk와 jre가 설치된 모습.
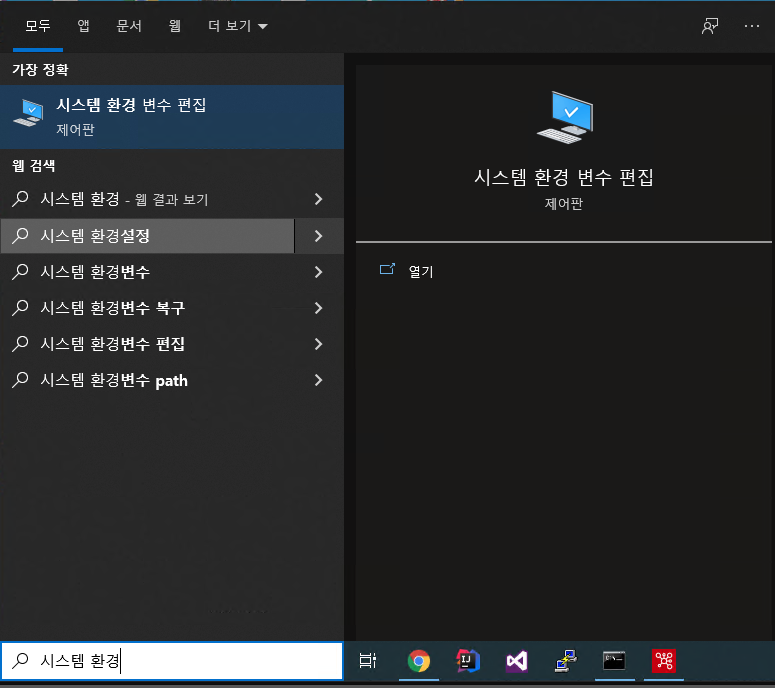
제어판 -> 시스템 환경 변수 편집 클릭 후
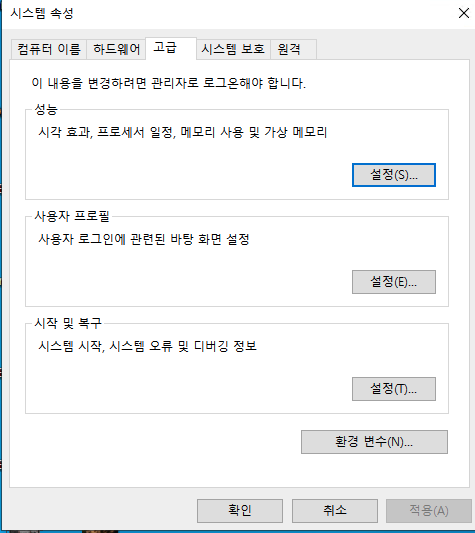
환경 변수 버튼 클릭
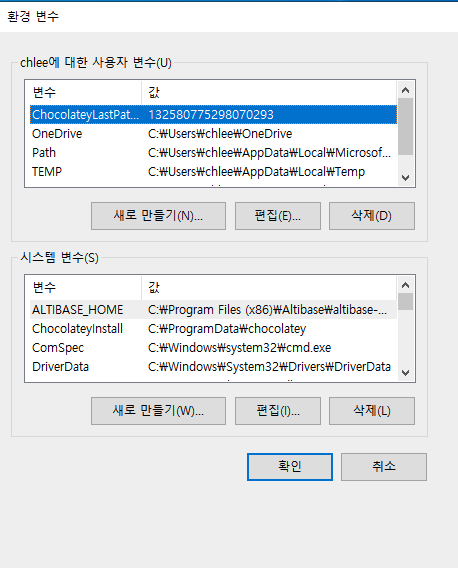
시스템 변수 -> 새로 만들기 버튼 클릭
1) PENTAHO_JAVA 환경 변수 생성
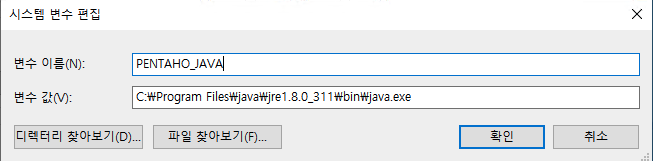
2) PENTAHO_JAVA_HOME 환경 변수 생성
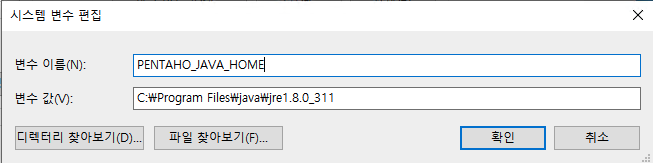
3) JAVA_HOME 환경 변수 생성
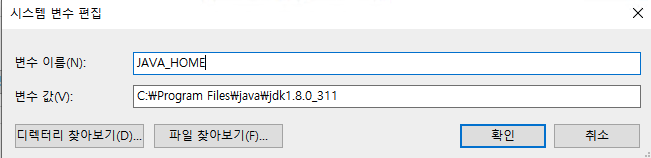
총 3개의 환경 변수를 설정 해두면, 기본적인 환경 설정은 끝났다.
이제 1번 Step에서 압축푼 폴더로 이동해보면 Spoon.bat 파일을 실행하여 pentaho 프로그램을 기동한다.
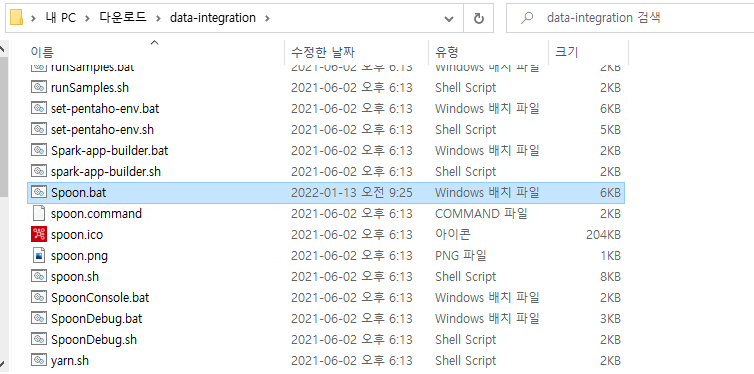
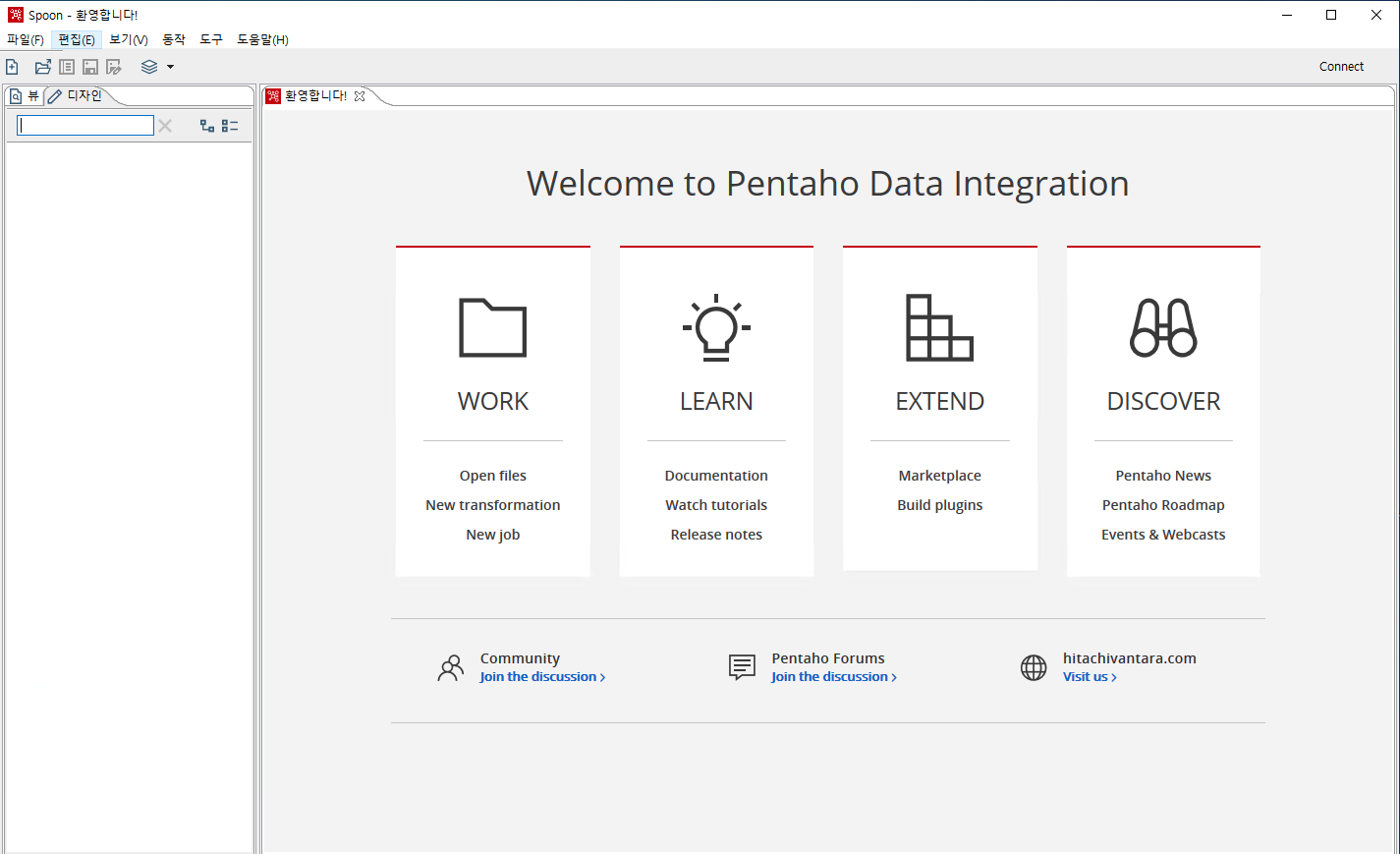
- 설치 끝 -
기존.. 차량에서 쓰던 갤럭시탭 s5e 를 네비용으로 썻었는데
매번 차량에 탑승할때 마다 테더링을 해줘야하는 버거로움에 빡쳐하던 중
최근에 그 정점에 달해 셀룰러 태블릿을 찾게 되었다.
다나와에 보면 15만원 후반대에 태클라스트 태블릿이 있지만
이번에 내가 산건 좀더 상위 버전의 T40 Plus이다.
실제 광고에 올라온 이미지를 보고 태블릿을 사면 낚이게 될것이다.
왜냐면 광고 이미지와 실물의 배젤차가 매우 크기 때문..
하지만 셀룰러가 된다는 점에서 이 제품을 선택하게 되었다.




대략적인 패키징은 이렇게 되어있고 충전기는 포함되어있지 않다.

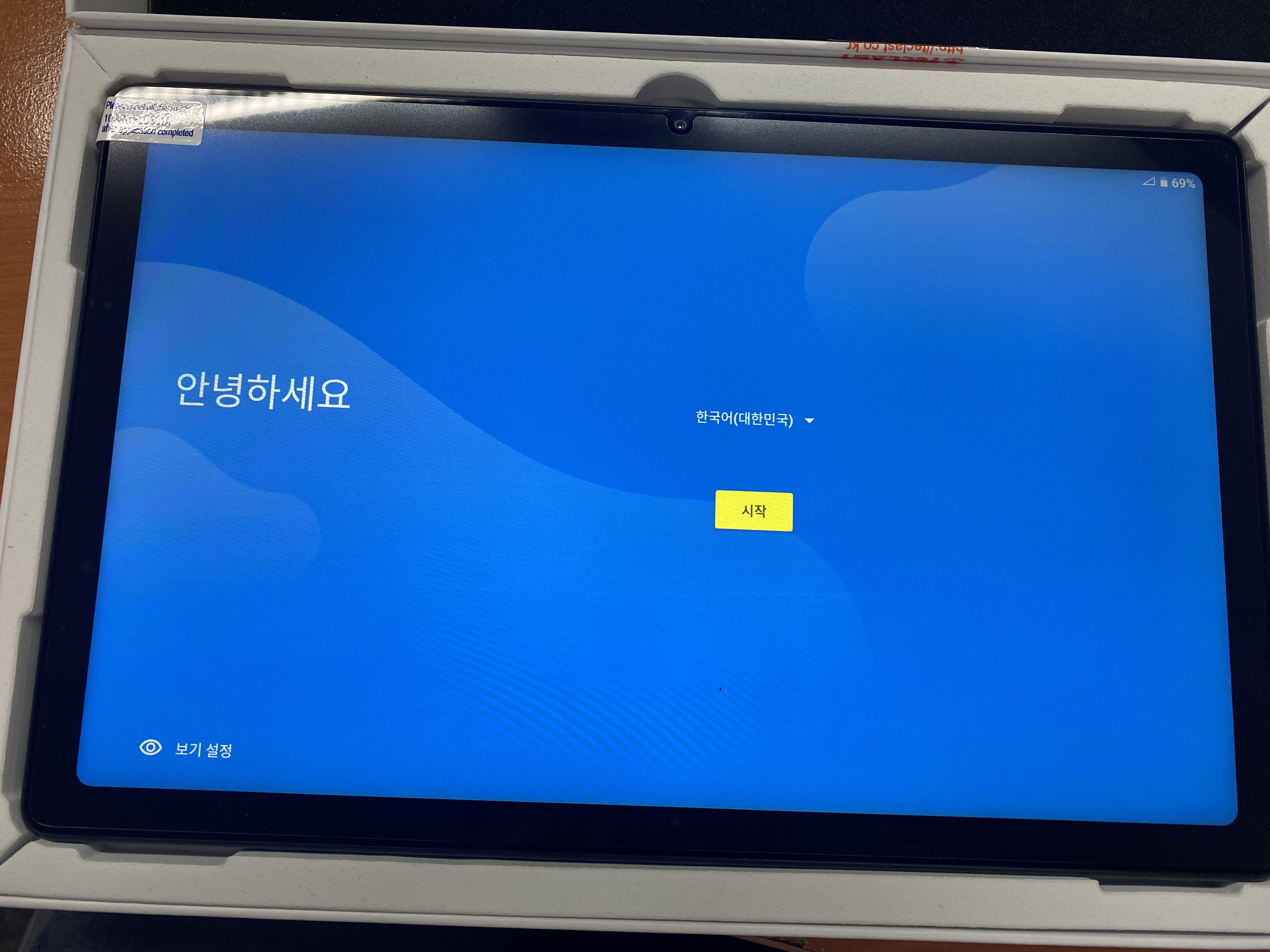

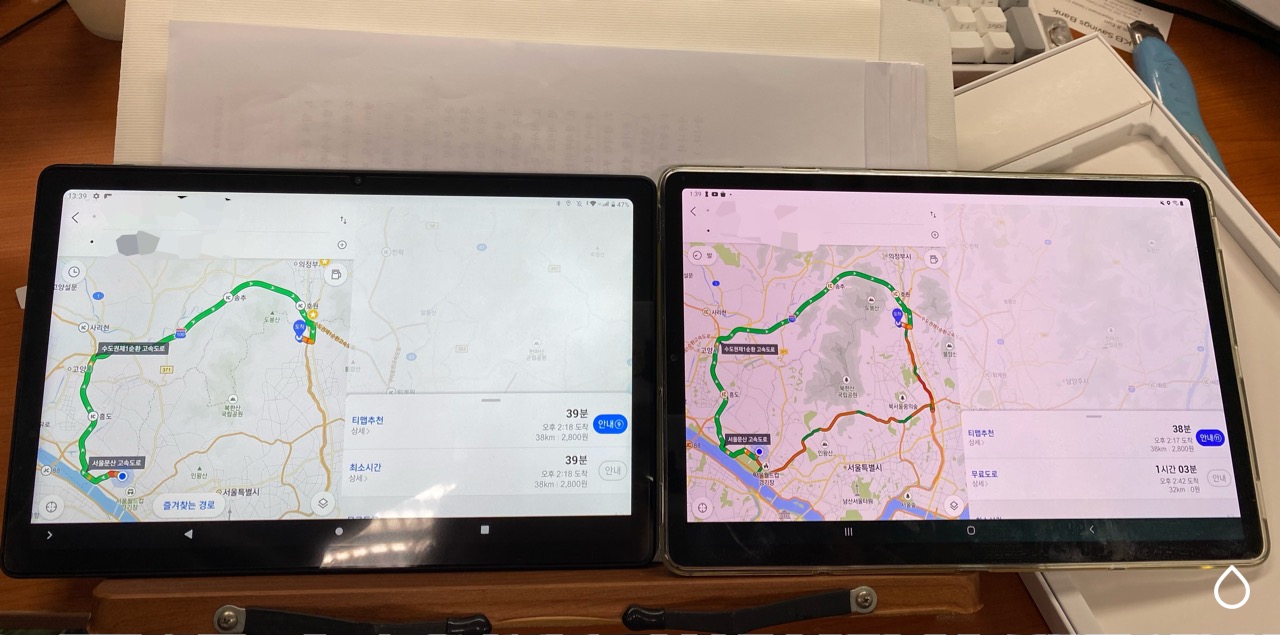
왼쪽이 t40 plus 오른쪽이 s5e
전반적으로 s5e가 배잴, 디스플레이크기 해상도가 더 높았다.
또한 삼성 one ui에 익숙해진 나로써는 쌩안드로이드는 매우 불편하다.
간단하게 정리하면
장점 :
- 매우 저렴한 셀룰러 태블릿
- 가성비 좋은 스펙 (디스플레이, 램, 저장공간)
단점 :
- 두꺼운 배젤
- 해상도가 생각보다 아쉬움 (애매한 해상도로 넷플릭스 hd화질 못 봄)
- GPS 부정확함 (못 쓸정도는 아니지만 한번씩 경로 못잡거나 할 경우 있음)
차량에서 네비용도로만 쓸 태블릿이기에 t40 plus로도 충분할꺼라 생각된다.

| [Window 설치] 이 디스크에 Windows를 설치할 수 없습니다. 선택한 디스크가 GPT 파티션 스타일입니다. 오류 해결 방법 (2) | 2019.02.16 |
|---|---|
| 정보처리기사 실기 2회차 합격 후기 (0) | 2018.08.17 |
| 2018 정보처리기사 실기 2회 가답안 및 후기 (0) | 2018.06.30 |
httpie란?
파이선에서 개발된 유틸리티로 http 개발이나 디버깅 용도로 사용된다. 사용성이 쉬우면서 json이 내장되어있다. 가독성이 뛰어나며 기타 장점들이 있음.
보통 리눅스나 맥에선 yum, apt, brew로 httpie를 땡겨오면 설치가 되지만 윈도우에선 파이선을 설치하여 pip로 설치해야한다. (https://httpie.org/doc#installation)
설치하기
1. https://www.python.org/downloads/ 에서 파이선 설치한다.


선택 옵션에서 pip 기능 체크후 설치를 진행한다.
설치 경로는 미리 기억해두자.

cmd를 실행하여 py를 입력하면 파이선 구동된 모습 확인가능.
2. 시스템 환경 변수 등록
시스템 환경변수는 환경 변수 -> 시스템 변수 -> path에 새로만들기 하여 추가한다.
C:\Users\luji\AppData\Local\Programs\Python\Python38-32\Scripts(내 PC의 경로) 파이선\Script폴더 경로까지를 입력한다.

3. httpie 설치
cmd창에 아래의 명령어 입력
pip install -U httpie

4. 예제 확인
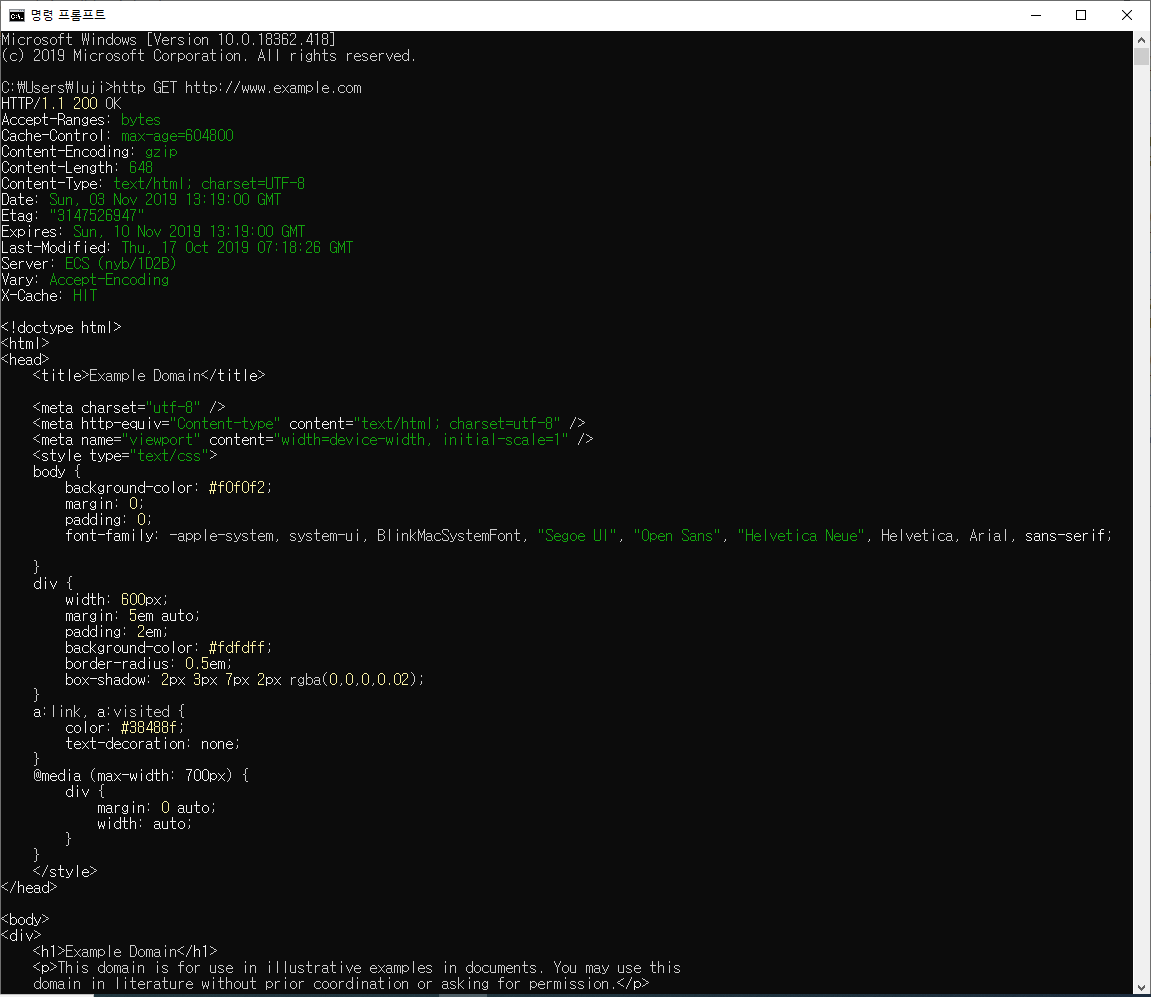
cmd에 아래의 명령어를 입력하면 응답을 확인할 수 있다.
http GET http://www.example.com
1. 터미널로 프로젝트 폴더 경로까지 이동
$ cd /User/luji/프로젝트
2. Git 설정파일 등록
$ git config credential.helper store
3. Git 명령어 실행
$ git pull
4. 사용자 정보 입력
이단계에서 사용자 정보를 입력하면 이후 부터 비밀번호를 묻지 않음
기존 도커 컨테이너로 실행한 Gitlab을 백업 복구하는 방법을 찾아 보았다.
생각보다 간단하게 명령어로 백업파일을 생성하고 복구할수 있도록 설정이 되어있어서 간편한것 같아서 정리해두기 위해 글을 쓴다.
$ docker exec -t <컨테이너 이름> gitlab-backup create
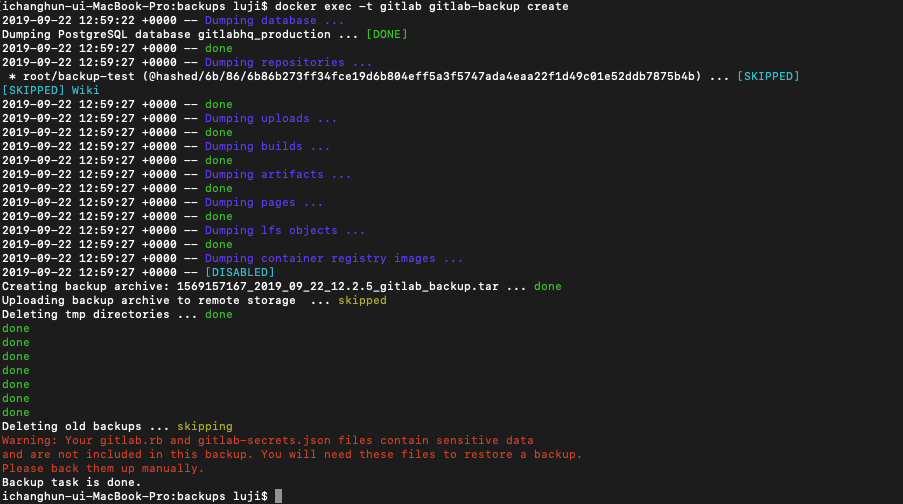
위의 명령어를 실행하면 도커를 생성할때 잡아둔 볼륨 디렉토리로 backup파일이 생성된다.
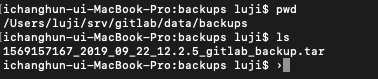
나같은 경우엔 볼륨 경로는 /Users/luji/srv/gitlab/.. 으로 잡아 두었기 때문에 백업파일의 생성 경로는 /Users/luji/srv/gitlab/data/backups 디렉토리에 저장되었다. 생성된 파일명은 ~~_gitlab_backup.tar으로 tar압축파일이 생성된다. 이제 이 tar파일을 따로 저장하여 백업하고자하는 머신으로 파일을 옮긴다.
나는 하나의 머신에서 테스트를 위해 기존에 실행중인 컨테이너를 삭제한뒤, 생성된 볼륨 디렉토리를 모두 삭제한 다음 새로운 컨테이너를 생성하였다. 이렇게 생성된 컨테이너는 모든게 초기화된 초기 상태의 컨테이너이다.
$ docker exec -it gitlab gitlab-backup restore
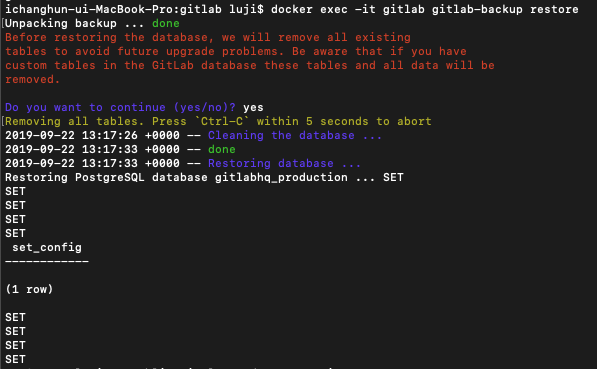
Postgres DB를 백업파일로 복구 하는 모습이다. 끝~
| [Docker] Gitlab CE 설치하기 (0) | 2019.09.21 |
|---|
Gitlab 에서는 CE와 EE제품으로 깃 서비스를 다운로드받아 설치할 수 있도록 제공해주고 있다.
CE제품에는 기본적인 GitLab의 기능들이 포함되어 있으나 심화되는 기능들은 EE에 포함되어 있다.
하지만 기본적으로 제공해주는 기능도 충분히 많으며 공짜이기에 CE로 설치를 진행하도록 하겠다.
설치를 위한 바이너리 파일도 존재하나 간단하게 설치하기 위해서 도커 이미지를 이용하여 설치를 진행할 예정.
(나중에 시간이 된다면 Ubuntu에 직접 올려 서버로 관리해보려고도 한다.)
일단 Mac에 설치된 도커를 이용하여 도커허브에 올려져있는 이미지를 다운받도록 하겠다.
$ docker pull gitlab/gitlab-ce:latest

$ docker images

gitlab/ce 버전의 이미지가 정상적으로 pull된것을 확인 할 수 있다.
$ docker run --detach \
--hostname 127.0.0.1 \
--publish 4443:443 --publish 8080:80 --publish 222:22 \
--name gitlab \
--restart always \
--volume /srv/gitlab/config:/etc/gitlab \
--volume /srv/gitlab/logs:/var/log/gitlab \
--volume /srv/gitlab/data:/var/opt/gitlab \
gitlab/gitlab-ce:latest
위의 옵션을 간단하게 설명하자면 hostname은 깃의 호스트 이름이다. 추후에 깃 프로젝트를 생성후 clone을 하게 되면 호스트이름을 베이스로 주소를 생성한다.
publish 옵션은 깃 이미지 내부에서 사용될 포트번호와 실제 머신의 포트번호를 맵핑해주는 옵션, http, https, ssh를 사용하기 위해서 자신에 맞는 포트를 설정해준다.
name 옵션은 깃 이미지 생성시 부여할 이름 이며, restart always는 도커 실행시 항상 시작되도록 설정 하는 옵션이다.
그외 볼륨 옵션은 깃 데이터를 백업하기 위한 저장 경로이다.

정상적으로 컨테이너가 생성된뒤 구동된 모습을 확인할 수 있다.
머신 성능에 따라 깃 컨테이너가 완전히 올라가는데에는 시간이 걸릴 수 있다.
http://127.0.0.1:8140/로 접속하면 도커 이미지로 올라가있는 깃랩에 접속 할 수있다.
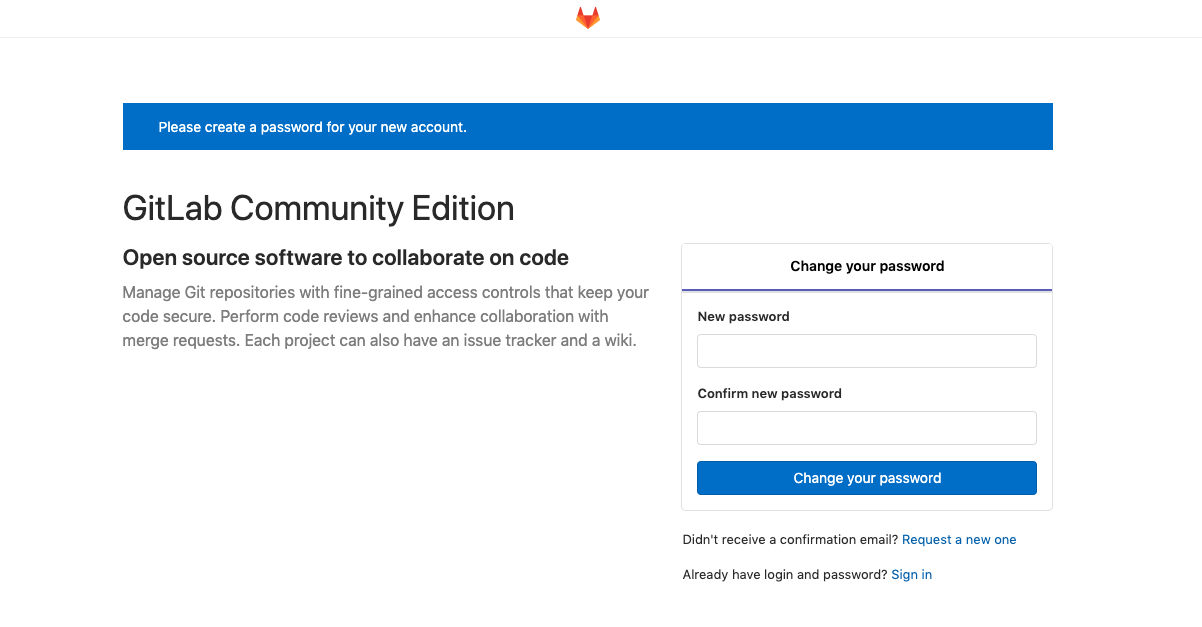
초기화면은 아래와 같이 root(Admin계정)의 비밀번호를 초기화하는 페이지가 출력된다.
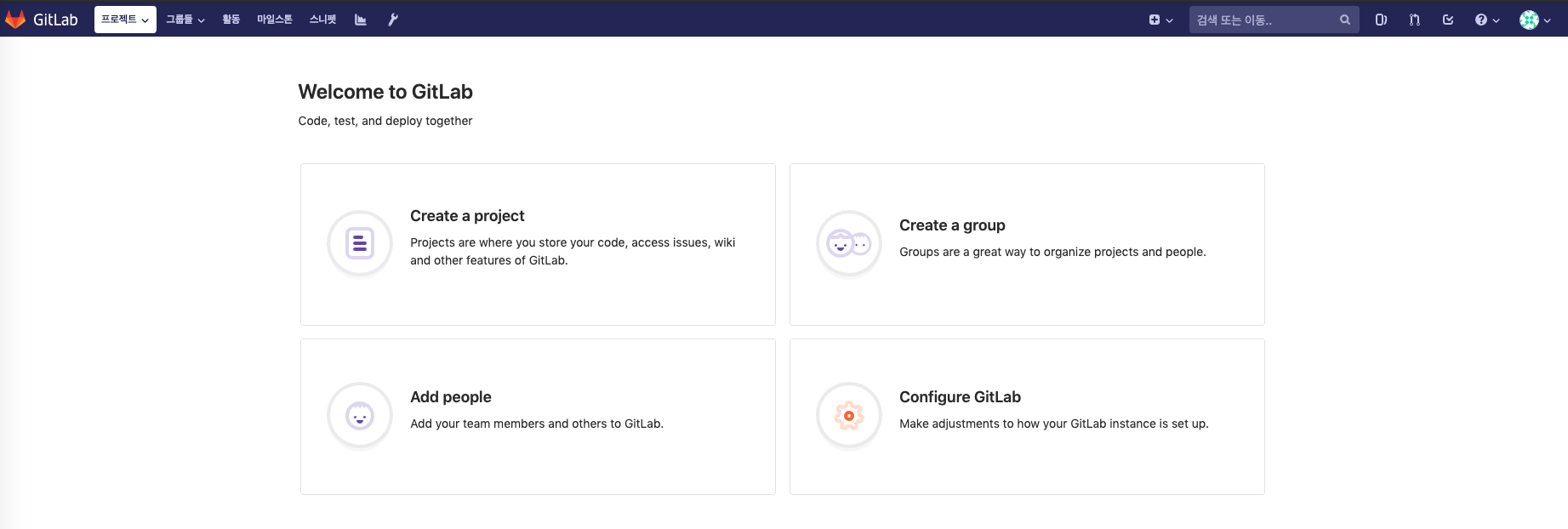
root계정으로 로그인하면 아래와 같은 화면이 보이는데 그러면 정상적으로 설치가 완료된 모습이다.
이제 사용자를 추가하고 엑세스토큰을 발급받아 깃을 사용하면 된다.
| [Docker] Gitlab CE 백업/복구 하기 (0) | 2019.09.22 |
|---|
간단한 Web 프로젝트를 Spring Boot로 만들었는데
이상하게 Tomcat에 War로 올리면 404 에러로 경로를 못찾는 현상이 발생했다.
덕분에 몇시간을 날렸는데 이유는 간단했다..
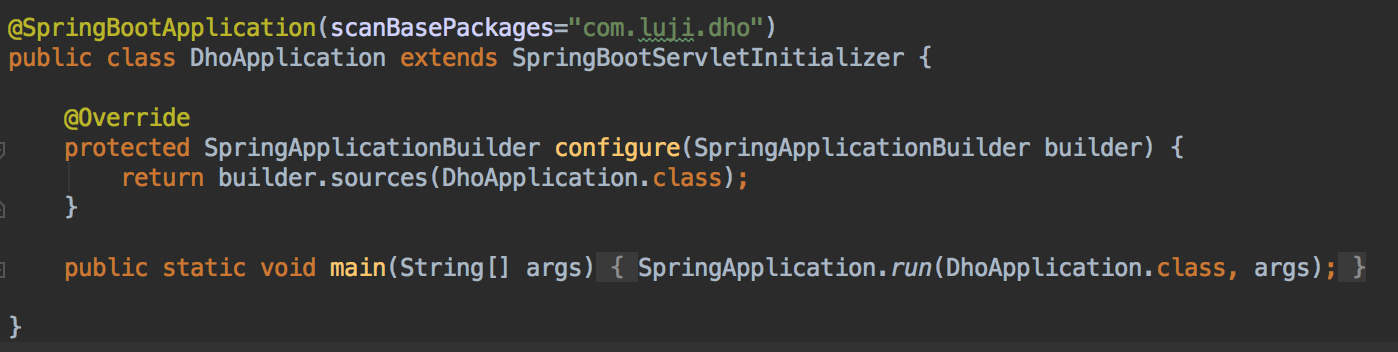
Spring Boot의 Main 클래스에 SpringBootServletInitializer를 상속받지 않아서였다.
일반적인 Spring Framework에서는 Web.xml에 DispatcherServlet을 등록하는 작업이 필요했다.
Servlet 3.0에서는 web.xml이 없이도 배포가 가능 해졌는데 Apache Tomcat 7부터 지원을 한다.
web.xml의 역할을 WebApplicationinitializer 인터페이스를 구현하여 프로그래밍으로 ServletContext를 구현할 수 있도록 바뀐것이다.
SpringBootServletInitializer는 WebApplicationinitializer의 구현체이다.
SpringBootServletInitializer를 이용하여 WebApplicationContext를 생성하여 Servlet Context에 추가할 수 있다.
나 같은 경우에는 프로젝트에 web.xml도 없었고, WebApplicationinitializer를 구현한 SpringBootServletInitializer도 없었기 때문에 Tomcat에서 URL의 요청을 받아드릴수가 없었던 것이다..
SpringBootServletInitializer를 상속 한다는건 결국 Tomcat과 같은 Servlet Container 환경에서 Spring Boot Application을 동작 가능 하도록 Web Application Context를 구성한다는 의미이다.!
나와 같은 삽질은 다른 사람들은 하지 않았으면....
| [Spring Boot] 스프링 부트에서 CORS 전역 설정하기 (0) | 2019.04.21 |
|---|---|
| [Spring] JUnit의 어노테이션과 메소드 (0) | 2018.09.10 |
| [Spring] IoC와 DI (0) | 2018.09.10 |
RHEL 기반인 CentOS7에 postgreSQL을 설치하는 포스팅이다.
이전에 포스팅한 LXD에 올린 Centos7 컨테이너로 진행할 예정인데 일반적인 환경과 크게 다를건 없을것 같다.
1. http://yum.postgresql.org/ 에 접속해보면 설치가능한 버전과 지원하는 OS를 확인할 수 있다.
2. 저장소를 설치
-> sudo yum install https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm
3. 설치가능한 패키지 검색
-> sudo yum list postgres*
3. PostgreSQL 9.6 버전 패키지 설치
-> sudo yum install postgresql96-server postgresql96-contrib
4. DB 생성
-> sudo /usr/pgsql-9.6/bin/postgresql96-setup initdb
5. PostgreSQL 시작
-> sudo systemctl restart postgresql-9.6
or
-> sudo service postgresql-9.6 start
6. 부팅시 자동 시작되게 설정
-> sudo systemctl enable postgresql-9.6
이렇게 하면 PostgreSQL 서버를 설치하고 구동하는게 끝났다.
netstat -tnlp 명령어를 쳐서 아래와 같이 5432 포트로 서버가 구동되어있는걸 확인하면 끝.
[root@vm1 data]# netstat -tnlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 309/sshd
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 427/postmaster
tcp6 0 0 :::22 :::* LISTEN 309/sshd
tcp6 0 0 :::5432 :::* LISTEN 427/postmaster
접속 해보고 싶다면 psql 명령어를 이용해서 접속할 수 있다.
-> sudo -u postgres psql
참고로 psql 접속 종료 명령어는 \q
이제 생성한 DB를 외부에서도 접속 가능하게 설정을 수정해줘야 하는데 vi에디터로 몇 줄 고쳐주면 된다.
6. 외부접속 허용하기
-> cd /var/lib/pgsql/9.6/data/
-> vi pg_hba.conf
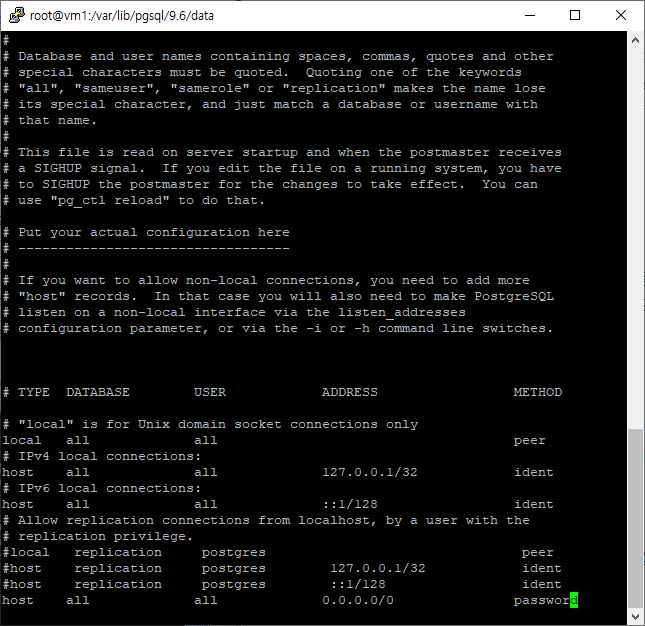
스크린샷처럼 맨 하단 라인에 아래의 내용을 추가한다
host all all 0.0.0.0/0 password
그리고서 저장 후 vi를 종료 (:wq)
이제 마지막으로 postgresql.conf 파일을 수정
-> vi postgresql.conf
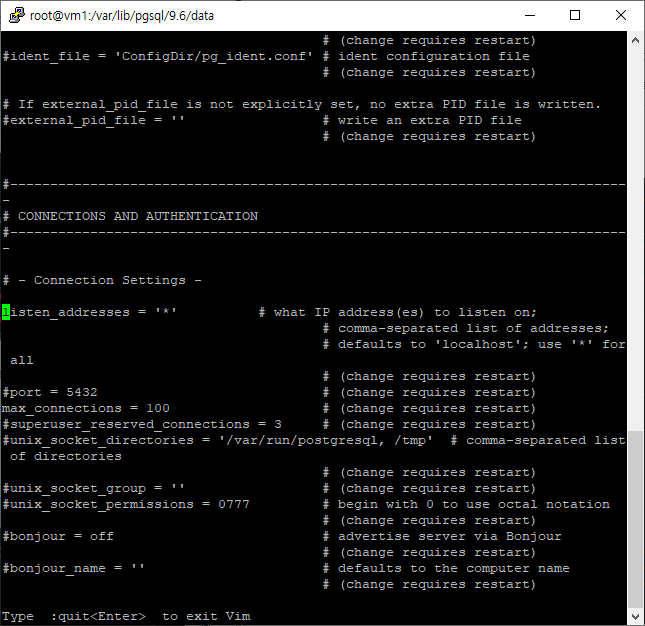
? 명령어를 사용해서 listen 검색 후 listen_addresses = '*' 로 수정한다. (주석 제거)
마찬가지로 저장 후 vi 종료
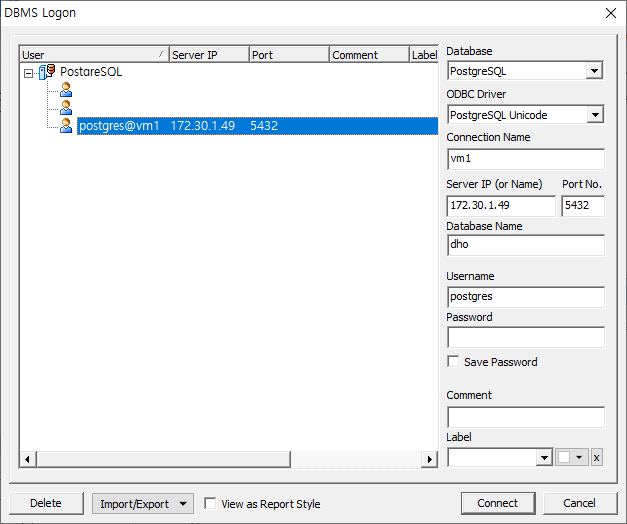
Orange Ade로 리눅스에 올린 PostgreSQL을 접속해보니 잘된다.
혹시 위의 설정까지 했는데 안된다면 리눅스의 방화벽을 해제하길..!!
| [Linux] CentOS7에서 LXD 설치하기 (0) | 2019.05.29 |
|---|---|
| [Linux] tar, tar.gz 파일 명령어 (압축하기/압축풀기) (0) | 2018.09.02 |